Recent Projects
Quantum Randomness from FPGAs
Status
Commercialized at Arbitrand
Available to License
Years
2021-Current
Value Proposition
First TRNG in the cloud
scalable to terabits per second
Key Artifacts
TRNG IP for Xilinx Ultrascale+ and Alveo; AWS machine image
As of 2021, clouds still did not have a good solution for true random number generation for systems that needed it. Our solution was to use FPGA instances available in AWS and Azure to generate true random numbers, and software to distribute them over the network to systems that need them.
In doing so, we created a circuit that extracts shot noise from FPGA primitives. This makes random numbers that are exceptionally high-quality and immune to interference.
In a datacenter environment, our TRNGs can be put into servers that can produce and distribute 160 Gbps of true random data each. One rack of these servers scales to terabits per second in a 10 kW power footprint.
Division by Iterative Approximation for Small Microcontrollers
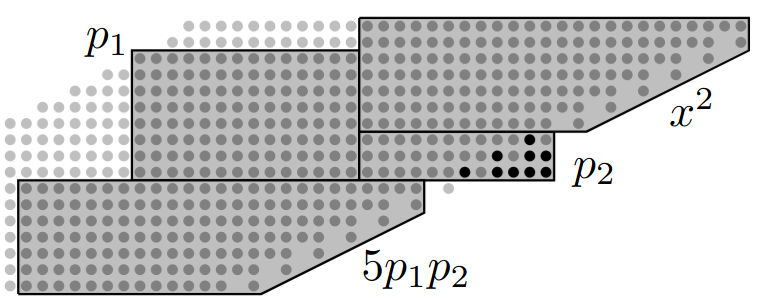
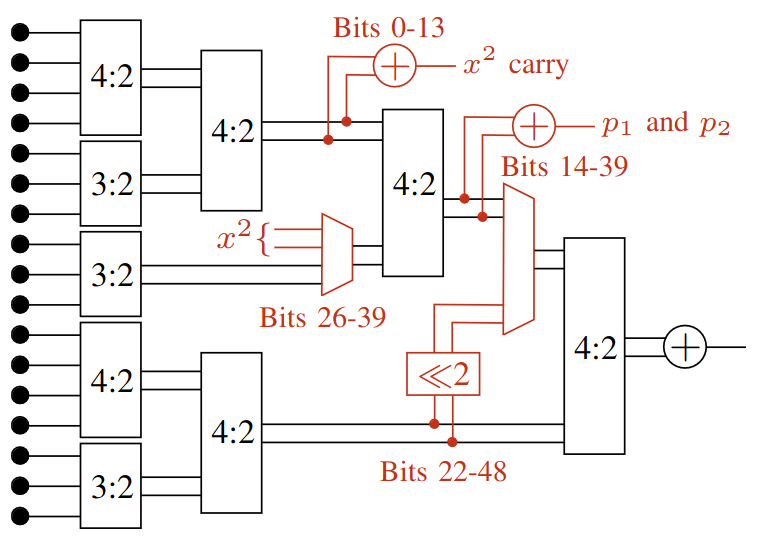
Microcontroller designers used to have to choose between division circuits that are small, but compute division results one bit at a time (restoring and non-restoring division), and division circuits that are fast, but large, using kilobyte-sized lookup tables and iterative refinement algorithms.
Our IP computes an initial approximation for an iterative division algorithm in a smaller circuit than a lookup table, which can be combined with a 32x32 multiplier to reduce its total area cost to <400 added logic gates.
As a result, our IP can be used to compute 32-bit integer divisions in <9 cycles, compared with 32 cycles for slow division methods. Including a control state machine with early termination, an integer divider based on our IP costs approximately 1000 equivalent gates compared to a system with no division. This also extends to float32 division in 5 cycles and float64 division in 8.
Status
Completed and Integrated
Published at ARITH 2023
Years
2022-2023
Value Proposition
3-4x faster division at a cost of <1000 logic gates
Key Artifacts
SystemVerilog code for integer/floating-point Mul/Div unit

